Download data
Dowloading your dataset to a local system can be done by cloning your repository. A clone is a local version of your dataset repository. It is still linked to the repository so you can make changes locally and 'push' them back to the repository. See our guide on how to work locally.
We use git LFS for handling large files
If you are familiar with git and GitLab or Github, most of this will be known. However, note that we deal with dataset repositories that carry large files, and we use git LFS to handle these. If you are unfamiliar with git LFS we recommend you still read through the following guide.
To handle data repositories with large files or LFS files(1) the git extension LFS is needed. With the extension the files get correctly tracked and when preferred, the repositories can be cloned without downloading the large files.
- LFS stands for large file storage. You can see a
LFSlabel behind the large.niifiles.
Install git lfs
Open the command line interface, and enter the following command:
git lfs install --skip-smudge
Using the --skip-smudge flag ensures that LFS files are not cloned by default. It is recommended to install Git LFS this way, regardless of whether LFS files are needed, as it prevents from accidentally pulling LFS files.
Smudge filter assumption
All our guides assume the --skip-smudge flag has been used!
Access token
To successfully clone a dataset repository, an access token is required.
This token is generated within your GitLab profile. To do this, navigate to "Your avatar > Edit profile > Access tokens > Add new token". Create a new token with scope "write_repository" (to be able to edit the dataset locally) or "read_repository" (to only download the data).
Do not share your token
Do not share your access token with others in any form as this token grants access to your dataset. Use a password manager to store your token as it not available later in the interface. In case you think your token is compromised, immediately revoke it.
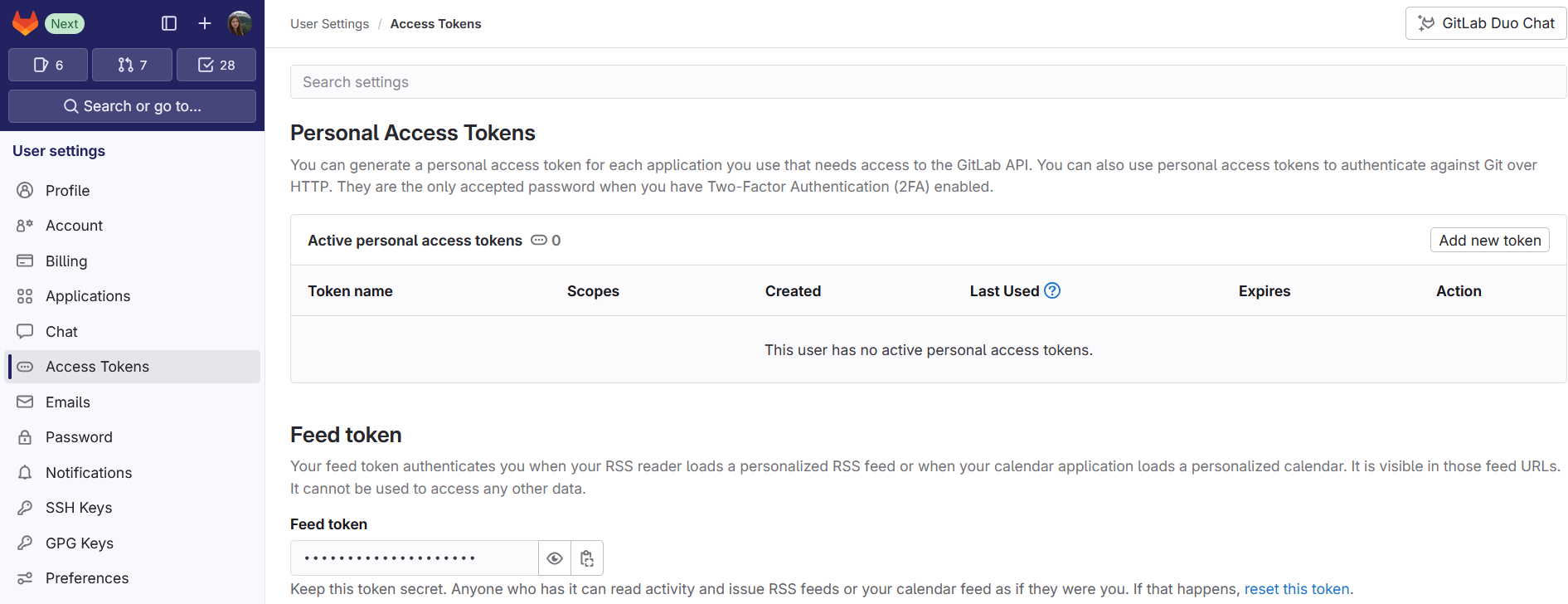
This token is later needed as password in the command line.
Cloning a repository without LFS files
You can clone a repository without the content of the lfs files, meaning they will appear as representative pointer files in your cloned repository. These pointer files can be moved, renamed, or deleted, and any operation performed on them will also affect the corresponding LFS files. However, the actual content of the LFS files remains inaccessible.
Open the command line interface, navigate to the directory where the repository should be stored, and enter the following command:
git clone <yourrepositorylink>
Getting the lfs files
If the contents of the LFS files are required (for example, for analysis), they can be pulled. It is possible to pull all lfs files in your data, or just a subset.
Cloning the entire repository with all LFS files
Disclaimer
Be aware that depending on the size of your dataset, this process may require significant resources, including network bandwidth, storage capacity, and time.
Open the command line interface, navigate to the directory where the repository should be stored, and enter the following command:
GIT_LFS_SKIP_SMUDGE=0 git clone <yourrepositorylink>
By setting GIT_LFS_SKIP_SMUDGE to false, the LFS files don't get smudged into representive pointer files anymore.
Pulling specific LFS files
It is also possible to clone specific LFS files by using filenames or filename patterns.
Open the command line interface, navigate to the directory where the repository should be stored or already is stored, and enter the following command with relativ path to the files:
git lfs pull --include="file1, file2"
This is a resource saving option if only a small fraction of files is needed.
You can also use a file pattern, for example, to download all runs of the stroop task within the first session of subject 01:
git lfs pull --include="sub-01/ses-01/func/sub-01_ses-01_task-stroop*"
Warning
If you do not use --include, all lfs files from the repository get pulled!